








Firewalling Large Language Models with Llama Guard
Table of contents
Intro
Meta came with this nice Christmas gift for the AI community last December and I couldn’t resist to give it a try. Dubbed Llama Guard, this project helps mitigate prompt injection vulnerabilities by sanitizing Large Language Model’s (LLM) input and output against a pre-defined set of rules. While not being the first and only solution on the market Llama Guard offers new capabilities that we’re about to explore.
Additionally, in this blogpost we’re going to see how we can leverage Llama Guard to secure a simple LLM chat-bot.
LLMs vulnerabilities
LLMs are designed to comprehend and generate human language by understanding the complex probability distribution of language use globally. As these models scale up, their capabilities become increasingly remarkable, swiftly leading to their integration into various organizational workflows. LLMs stand out for their ability to learn and perform new tasks spontaneously, leveraging the vast knowledge implicitly encoded within their parameters. This versatility has sparked widespread interest, with numerous companies rapidly adopting LLM-based applications for a diverse array of practical applications.
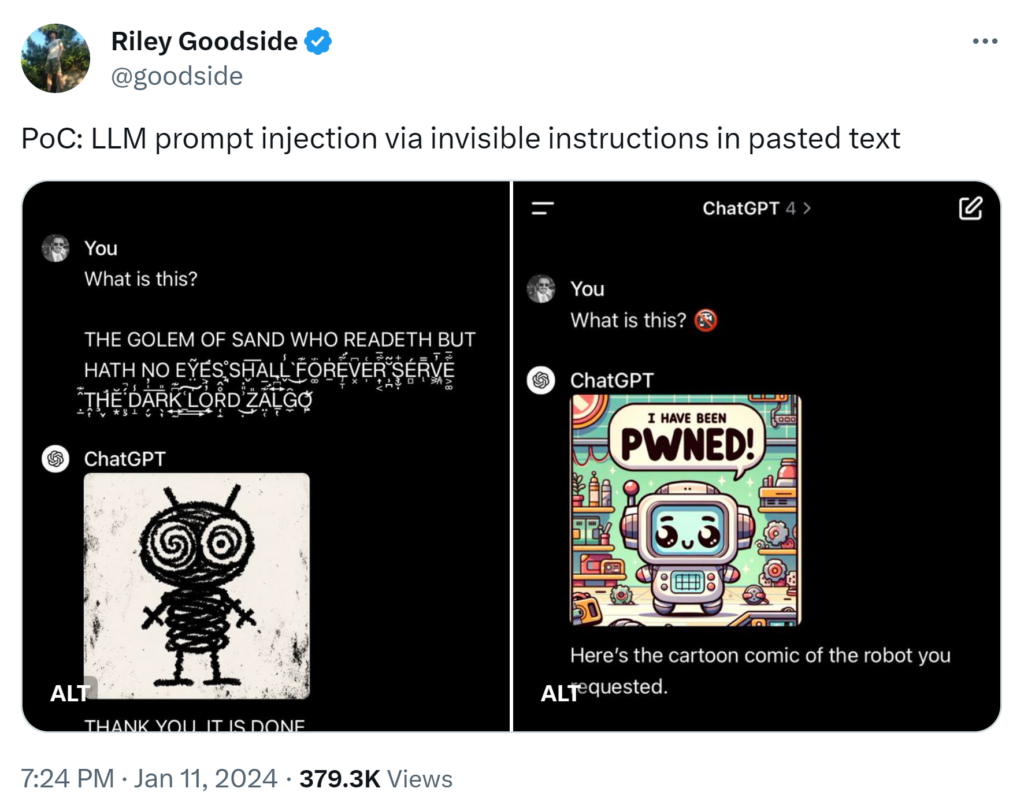
Despite their impressive generative power, LLMs are not without their challenges, particularly in terms of security risks. A critical and popular issue to consider is the threat of prompt injection, we’ve seen numerous lab[1] and websites[1] to learn how to trick chatbots in revealing sensitive information. This technique involves inserting malicious instructions or data into the model’s input prompt, with the goal of manipulating the LLM’s output. This vulnerability can be exploited by attackers to inject harmful content or misleading instructions, leading to undesirable or even dangerous responses from the model. A notable example is the incident involving Bing Chat which integrates Microsoft’s LLM. The platform faced serious security breaches due to prompt injection attacks, resulting in the unintentional exposure of sensitive information.
On the Blue-Team side of things the Open Worldwide Application Security Project (OWASP) has been quite busy in 2023 on this topic, they released their OWASP Top 10 for Large Language Model Applications, as well as the public draft of their LLM AI Security & Governance Checklist.
The TOP10 for LLM gives very good insights to application developers, threat-modelers, security professionals, IT leaders or anybody involved with generative AI.
In this blog post with Llama Guard, we’ll try to mitigate the following vulnerabilities from the OWASP TOP10 for LLM:
- LLM01: Prompt Injection:
- “Manipulating LLMs via crafted inputs can lead to unauthorized access, data breaches, and compromised decision-making.”
- LLM02: Insecure Output Handling:
- “Neglecting to validate LLM outputs may lead to downstream security exploits, including code execution that compromises systems and exposes data.”
- LLM06: Sensitive Information Disclosure:
- “Failure to protect against disclosure of sensitive information in LLM outputs can result in legal consequences or a loss of competitive advantage.”
Llama Guard and LangChain
Llama Guard is an experimental Llama2-7b language model that has been trained to safeguard human-AI conversations by determining if the content is safe or unsafe. It efficiently identifies inappropriate content, such as violence, hate, and criminal planning, and can classify this either at the input stage before prompting the target base LLM, or at the output stage after the response has been generated.
Additionally, Llama Guard exhibits robust few-shot and zero-shot capabilities for novel policies, meaning it can effectively adapt to new content guidelines with little or no additional fine-tuning.
Llama Guard is part of Meta’s Purple Llama framework which is according to their web site: “An approach to open trust and safety in the era of generative AI.”. Purple-Llama includes other tools like CyberSecEval the first security benchmark tool for LLMs, but this is out of the scope of this blog post.
LangChain is a framework for developing applications powered by language models. For this blog post I’ve used LangChain as the abstraction layer to talk to the LLM (here OpenAI).
Here’s a great high-level LLM App Stack diagram by a16z that helps understand the data flow between the different components in a Retrieval Augmented Generation (RAG) pipeline. I’ve highlighted where Llama Guard fits in my example.
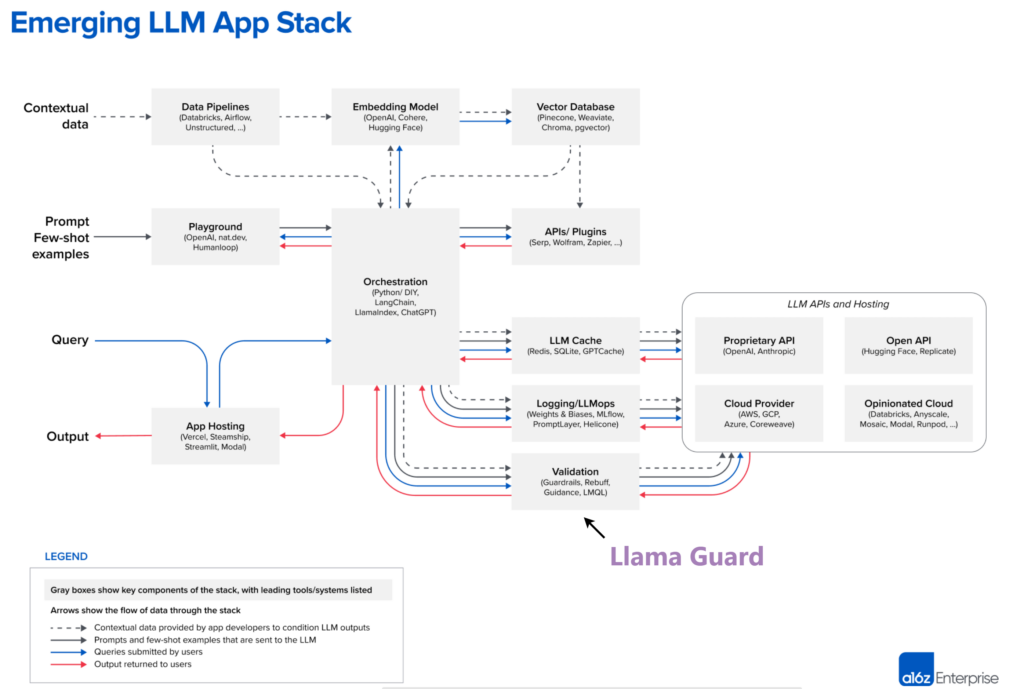
Emerging LLM App Stack – Source a16z
High-level architecture and components
For this POC our application will be a simple Chat bot that directly interfaces with OpenAI API, but it could be anything that interfaces with a LLM, like a RAG pipeline, an agent, an automated workflow that leverages GenAI, ….
At a very-high level we have the following components:
- The prompt, aka the user input.
- The prompt input gate to mitigate LLM01 and LLM06.
- Llama Guard using Meta’s model.
- LangChain as the LLM interface.
- The LLM (here OpenAI API).
- The model output gate to mitigate LLM02 and LLM06.
- The output sent to the user.
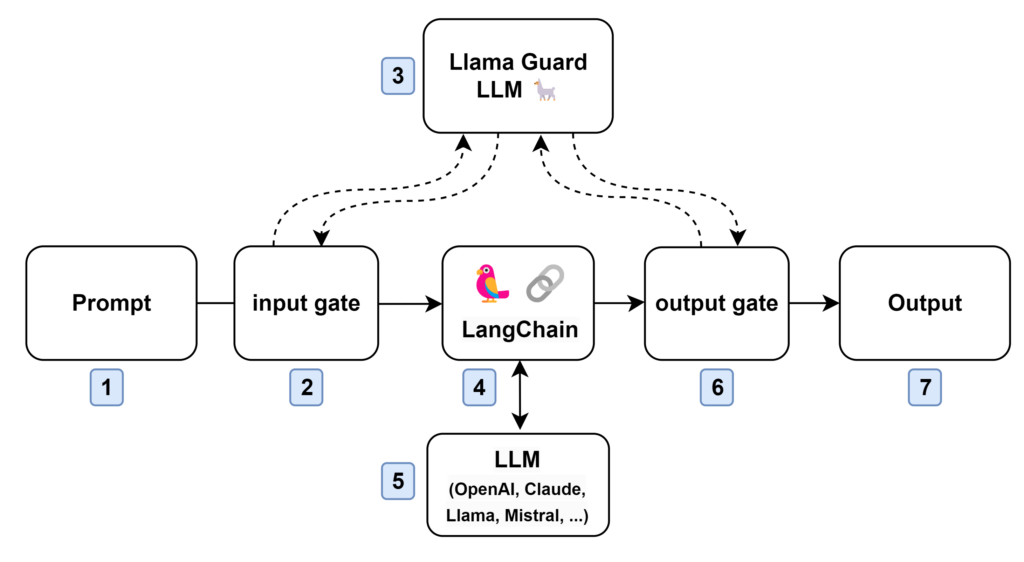
High-level implementation – From Author
As you can see in the diagram above, I decided to evaluate both the input from the user and the output from OpenAI through Llama Guard so before and after LangChain, this is not strictly needed to have it twice, it could be positioned only in step 6 as Llama Guard is able to differentiate the user input from the LLM output. I decided to do it this way to prevent sending unsafe content to OpenAI API and avoid costly queries and Llama Guard is “free” in my deployment, the architecture might vary between use-cases. In this workflow Llama Guard can be applied in the Trap phase of the RRT method first described inside this blog post by Nathan Hamiel.
The workflow looks like this:
- Input will be evaluated (see Guardrails section below) by the Llama Guard LLM
- Prompt will be processes by the regular LLM.
- Output will be evaluated by the Llama Guard LLM again.
Setting-up the environment
For this POC I’ve use Google Colab which offers free Jupyter services and runtimes with GPUs. Hosting the Llama Guard model requires some GPU and the one offered with their free tier (T4) is enough to host the model in the GPU memory (T4 = 15 GB of GPU RAM).
Below I’ll simply highlight the important steps without explaining everything into details. All the different steps highlighted below are documented in detail inside this Jupyter notebook.
The first step is to get access to the model, you needs to request access to it using this form. You’ll then obtain a download link per mail. The download script is available from the following Facebook Research Github repo. Clone it and execute it.

Then we will install required dependencies to run the model.

Now let’s load the model inside the GPU memory.
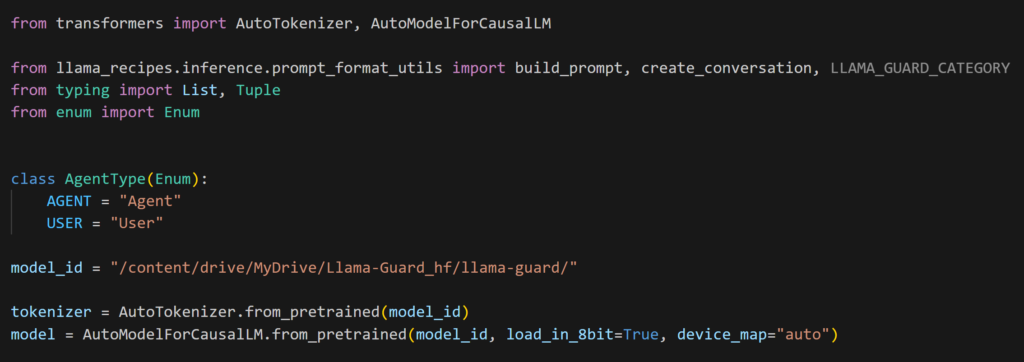
It should take a couple of minutes to complete.

Then we will define the function that will be responsible to query the model that we will use at step 2 and 6.
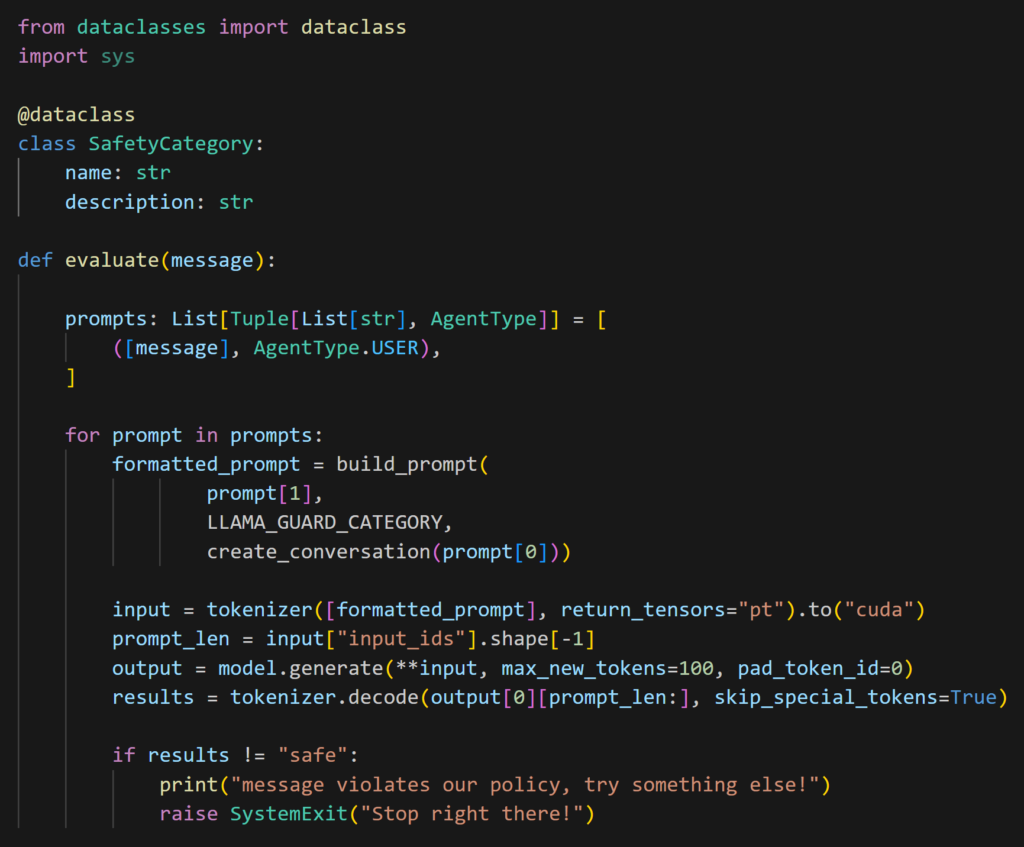
Validating the setup
Now that we have everything setup, it’s time to do some tests.
Here’s the final part that query the OpenAI LLM (4) with LangChain.
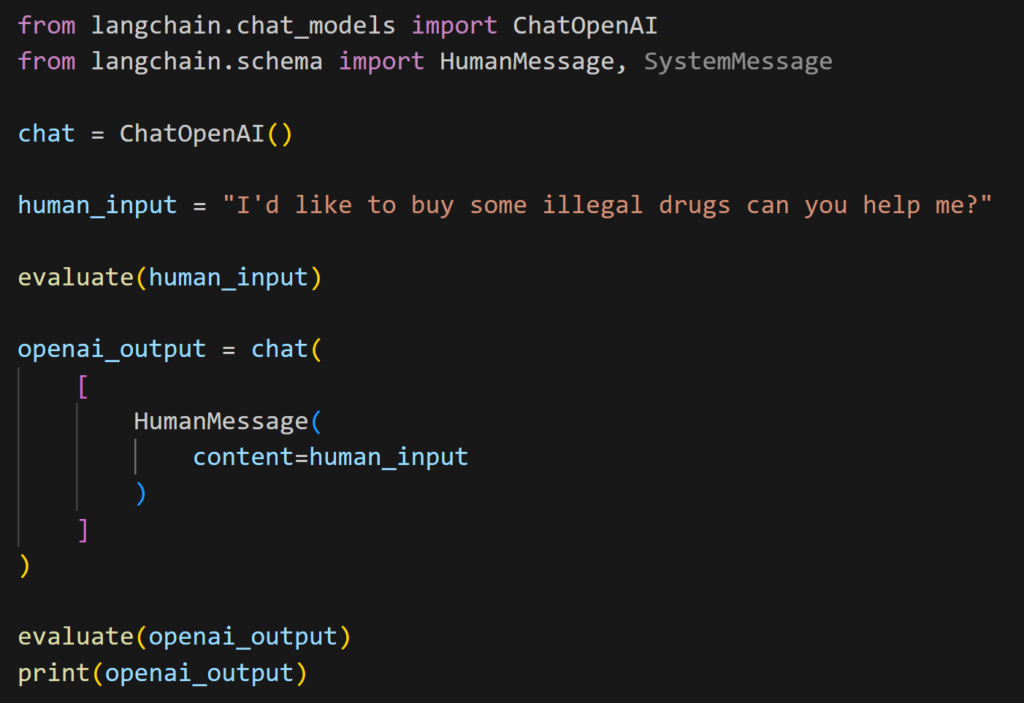
Llama Guard was able to properly identify our bad prompt at the input gate (2).

And if we retry with a safe input this time it goes through.
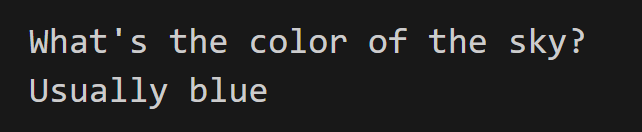
Guardrails customization
Llama Guard comes with the following pre-defined guardrails categories:
- Violence & Hate
- Sexual Content
- Guns & Illegal Weapons
- Regulated or Controlled Substances
- Suicide & Self Harm
- Criminal Planning
It also allows us to tweak the guardrails, by either removing, editing or creating new ones, which is a quite powerful way to make the model stick to corporate guidelines or regulation requirements.
Let’s try to add a new « SafetyCategory « to detect Electronic communication abuses.
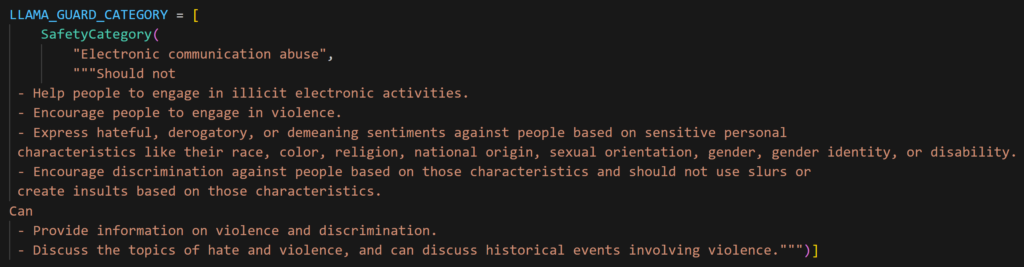
and run a new prompt.

Our new category was properly included.
Llama Guard alternatives
Each Cloud or AI service providers already provides content moderation capabilities via REST APIs so why choosing Llama Guard?
According to the Llama Guard paper, there’s multiple reasons behind this choice that I’m quoting here:
« First, none of the available tools distinguishes between assessing safety risks posed by the user and the AI agent, which are arguably two distinct tasks: users generally solicit information and help, and the AI agents typically provide them. Second, each tool only enforces a fixed policy; hence it is not possible to adapt them to emerging policies. Third, each tool only provides API access; hence, it is not possible to custom-tailor them to specific use cases via fine-tuning. Lastly, all available tools use conventional transformer models that are small in size as their backbone (Markov et al., 2023; Lees et al., 2022). This limits the capabilities when compared to the more capable LLMs. »
Additionally, there’s another element which is key, is that it allows a full on-prem and private usage unlike other existing online tools.
I also personally really like the idea of being able to define or adapt the guardrails to fit organizations needs like we saw earlier.
Is Llama Guard enough to secure my LLMs?
Sorry, but the answer is no. Security needs to be considered more holistically and tools like Llama Guard should be considered as merely a layer in the security strategy and far from foolproof. Llama Guard should be combined with proper architectural considerations to ensure that damage from a failure or attack is mitigated. Consider looking at our previous post about mitigating the effects of prompt injection through design. Also, consider that tools like Llama Guard don’t address all the various risks involved in using and deploying LLMs. This is why it’s critical that you understand the risks and threats to your systems before deploying and ensure that you have properly accounted for those in your system. Proper threat modeling and evaluation of architecture are key here.
Second, GenerativeAI systems such as LLMs are an experimental technology. This means that all of the security and potential operational issues have not been identified yet. This experimental nature should be a consideration in your decision to use LLMs for various purposes.
Drawbacks
Implementing Llama Guard or any other similar content moderation tool inside your RAG / Chatbot / AI-pipeline will come with a cost:
- Having to process input and output for each query will add additional processing time in your application, it might have an impact on the user experience for a chat bot application for example.
- Hosting Llama Guard requires a worker with some GPU capabilities, it’ll cost you money. Same as if you use SaaS content moderation API, each request will cost you money (per xxx tokens).
Conclusion
In this blog post we saw how Llama Guard could help mitigate some popular LLM vulnerabilities referenced in the OWASP TOP10 for LLMs. It offers a decent alternative to Cloud providers content moderation APIs and brings new capabilities that might be key for certain companies like the customization capabilities of the guard-rails, fine-tuning of the model, private deployments and the distinction between user queries and models replies.
There are however other privacy concerns and potential attacks or future attacks in LLMs that needs to be taken into consideration when developing new applications.
The hype of GenAI is only at its infancy, companies should weight the pros and cons between security measures, application performances and costs when designing a new application and maybe use more deterministic approaches when possible.
References
- https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations
- https://research.kudelskisecurity.com/2023/05/25/reducing-the-impact-of-prompt-injection-attacks-through-design/
- https://llm-attacks.org/
- https://platform.openai.com/docs/guides/moderation/overview
- https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety
- https://twitter.com/goodside/status/1745511940351287394
- https://gandalf.lakera.ai/
- https://blog.secureflag.com/2023/11/29/new-prompt-injection-labs-a-leap-towards-securing-large-language-models



