








4 Roadblocks to Faster Threat Detection & Response and 3 Things You Can Do About It
In this blog on Managed Detection and Response, Kudelski Security’s Managed Detection and Response Team discuss four major issues familiar to any security leader who has wrestled with making threat detection and response more efficient. If you want to cut straight to the chase, check out our ModernCISO Guide on cyber resilience– it’s a practical guide to addressing the cyber resilience challenge.
Table of contents
The Reality: Your Current Detection Strategies Aren’t Working
I hate to be the bearer of bad news, but your current detection strategies aren’t working. Despite best efforts, 91% of attacks go under the radar with security teams identifying just over half of the breaches. I wish I could say there was some larger issue at play here, but this is largely a problem we’ve brought upon ourselves. We set up our Security information and event management (SIEMs) we categorize all of our alerts, and we put a response plan in place (hopefully). And yet, the problem persists. We’re doing all the right things, or at least we think we are. We and our technology, though well-intentioned, are getting in our own way, creating roadblocks where we should be creating fast lanes that accelerate time to detection and response. Meanwhile, attackers are sitting inside our environments, sometimes for months or more, and we don’t even know it until the aftershocks are felt.
These roadblocks occur because for years our approach to threat detection has lulled us into a false sense of security where we think more data (which just leads to more alerts) is going to help us stop a breach. What if I told you that we as security professionals can be more effective with fewer alerts from fewer data sources.
Sound crazy? I’m not the only one thinking this way. Here’s what Gartner has to say on the topic:
“Many customers fail with their threat monitoring, detection and response initiatives, because of the focus on monitoring a variety of log sources from whatever technologies they have deployed, instead of having the right sources generating telemetry and alerts, at the right time, in the right format, in the right locations.”
So, we know we’ve got issues, and we know we want to change. What should change look like? That’s what we’ll get into in this post. First, let’s dig a little deeper into what’s holding us back today.
The Four Roadblocks to Faster Threat Detection
Roadblock one: Most organizations get SIEM wrong.
Let’s start with the low-hanging fruit, here. We’re bad at SIEM.
Too dramatic? Here’s what I mean. SIEM was initially positioned as the solution to all of our security monitoring problems. It would pull all your security telemetry into one place, allowing us to centralize triage and initiate response activities. Great! But SIEM systems fail to deliver when fed irrelevant or excessive data . Plus, there’s so many of them it all becomes noise, a queue for some poor Security Operations Center (SOC) analyst to sift through.
To be fair, this really isn’t your SIEM’s fault. It’s only going to ever be as good as the data it’s collecting, and we’re feeding it some pretty bad data. If you have not set up your SIEM to collect the right (non-default) Microsoft Windows Event data or antivirus logs, then your SIEM is never going to tell you about the attack that’s using Cobalt Strike to move laterally throughout your network. This brings us to our next roadblock.
Roadblock two: Default configurations kind of suck
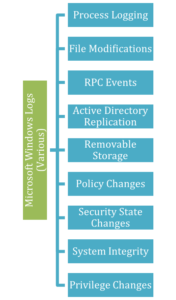 |
Take, for example, the default Windows logging configurations. If you plugged it in and turned it on, you’d be missing out on all these events. No alerts for changes to policies or files or privileges or the security state. No logs related to Remote Procedure Call (RPC) events or removable storage or system integrity. It’s so limited that we created a CFC client guide that tells our customers what the defaults should be. |

There. I said it. Default configurations are default. That means they’re designed with the lowest common denominator in mind. They don’t know your unique environment or the threats to it. They’re just there. And if you’re relying on default configurations for security alerting, you’re going to be missing critical pieces of information, leaving gaps in your defenses that could help you stop an attack earlier.
Roadblock three: We let devices dictate our detection strategy
You get a new intrusion detection system (IDS) tool. You look at all the types of alerts you can get from it, you categorize them, and you figure out a response plan. Which leaves you with thousands of alerts from that one tool. Plus a thousand from your firewall, another thousand from your cloud service provider and so on. It’s a lot to sift through, leading to alert fatigue and it may not even tell you all that much. An alert in your IDS may seem like no big deal in isolation. You need a common lens through which you can evaluate alerts coming in across all your relevant devices. At Kudelski Security, we call these lenses “use cases.” More on that in part two.
Roadblock four: Everything’s a priority
When everything’s a priority, nothing is a priority. And nowhere is that more true than threat detection and response. If you are set up to collect every log for every potential indicator of every potential threat, your team will quickly be overwhelmed with data, making it harder to discern actual threats. This leads to wasted resources and missed opportunities for preemptive action. You need to be able to see the forest through the trees.
Figuring out what those threats are requires a threat modeling exercise. Threat modeling may have once been considered a “nice to have” in the enterprise security space, but I’d argue, for the reasons above, that without it, you will end up running on a treadmill of alerts that never really gets you anywhere. The goal is continuous improvement. Start with the most important thing you can reasonably do today and then move on to the next. But you have to know where to start, and threat modeling can help you with that.
Three Strategies for Breaking Through
So, while there are many challenges, relating to everything from SIEMs, default configurations, device-led strategies, and competing priorities that can impede efficient threat detection and response, it’s not all bad news. Here are three things that can help.
1. Develop your use cases (aka your common “detection lens”)
I mentioned use cases before, in the context of alert fatigue that arises when we let devices dictate our detection strategy and evaluate alerts across devices through a common lens. A use case is a high-level threat detection priority, not to be confused with detection rules.
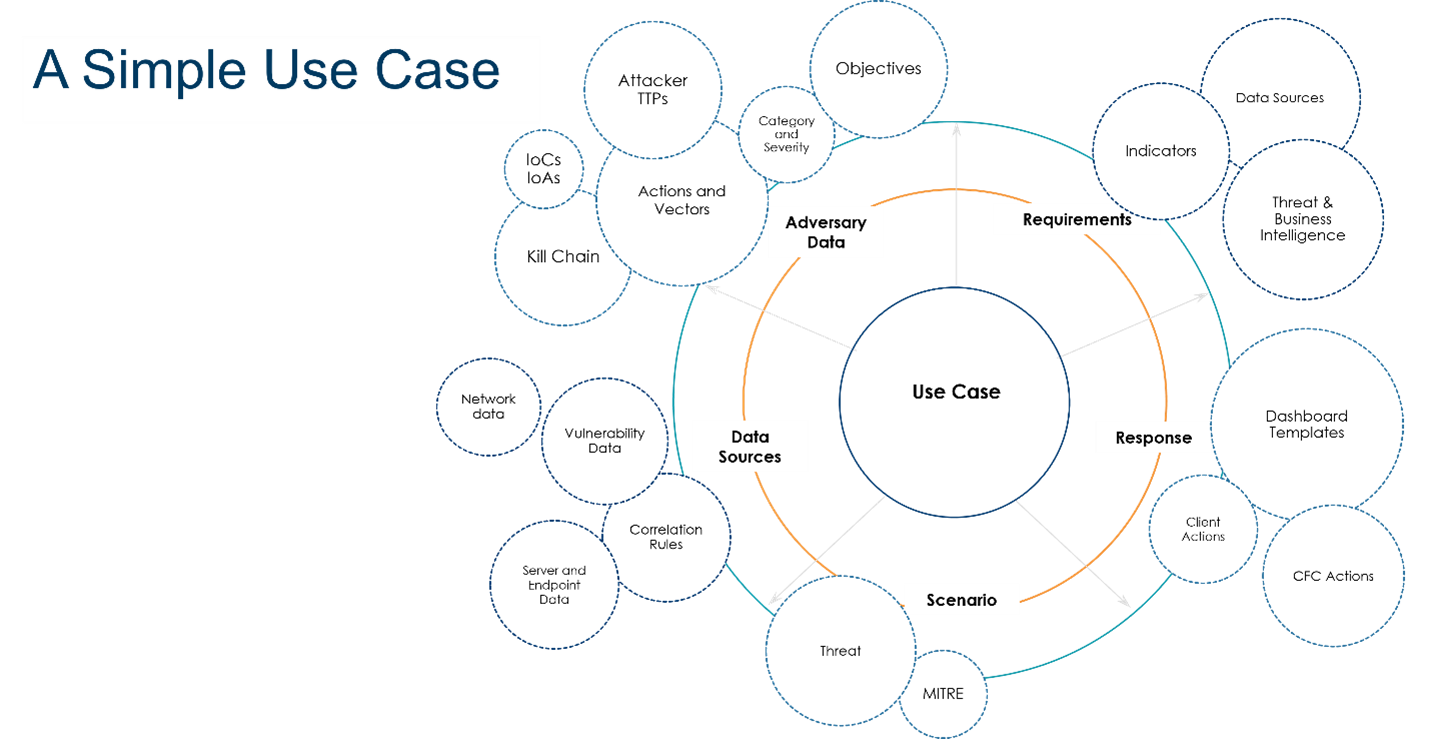
For example, phishing might be a threat detection use case for your organization.
While it seems simple, to fully understand each use case, we have to understand your adversary, their motivations and the techniques they use to move through the kill chain.
We also have to understand how that attack will play out within the environment (scenarios) and the data sources required to detect the attack.
Finally, we have to know how each of the parties involved in containment and remediation should respond.
Kudelski Security has developed its own use case framework based on our years of threat detection and monitoring experience. This framework includes 16 common attack vectors with scenarios mapped to the enterprise MITRE ATT&CK matrix. One use case could have upwards of a hundred scenarios, and these scenarios are what you’ll tie your detection rules to. Even if you’re not a client of ours, it’s helpful to think of your threat detection strategy in this top-down way.
2. Prioritize detection based on your threat model
Use cases provide the foundation for your threat detection strategy, but given the hundreds of potential scenarios and thousands of potential alerts, it’s still a lot to wade through. Threat modeling helps you understand the specific threats your organization faces, allowing you to prioritize detection based on real, rather than perceived, risks.
At Kudelski Security, when we onboard clients, we take them through a threat modeling exercise to identify the attacker groups targeting their geographic region and industry and the objectives of that group—e.g. ransomware, disruption of critical processes, political motivations, etc.
We also work to understand what we’re defending (from a technical and business perspective).
With their threat model defined, we can identify the Tactics, Techniques, and Procedures (TTPs) those threat groups use and map them to MITRE techniques. We may find that there are overlapping techniques between the groups.
Where we have the most overlap is where we’ll start with our detection strategy, then the second most, the third, and so on.
3. Collect the right data
It’s only after completing the two steps above that you’re ready to actually start collecting data and the right data is key to effective detection.You know the types of threats you’re most vulnerable to and the tactics, techniques, and procedures (TTPs) associated with those threats. Better yet, you know which tactics are shared across threats, helping you focus detection efforts where they’ll have the most immediate impact. This should give you a clearer picture of the sources and types of data you should be pulling into your SIEM.
As a rule of thumb, we always recommend collecting the following types of data. Nearly all the incident and response (IR) projects our team is brought into could have been detected with properly configured alerts from these sources.
| Microsoft Windows Logs (not just defaults) | Intrusion Detection Systems | Netflow | AntiVirus Logs | IaaS Cloud Logs |
| Mail Server / Gateways | Web Application Firewalls | Firewall Logs (accept & deny) | Authentication Data | Web Proxies |
I started this series out with some grim facts about our ability to successfully detect threats, so it’s only fair that I end with some good news.
You likely already have everything you need to improve threat detection and response. What matters is collecting the right data from the right sources to detect the right threats for your environment.
Get in Touch
Improving your threat detection and response doesn’t require starting from scratch, but instead refining and focusing your existing strategies and tools. Interested in elevating your security posture with our Next Generation Managed Detection and Response services?
We’re here to help you navigate these challenges and safeguard your environment against sophisticated threats. Contact us to explore how we can tailor our solutions to meet your specific needs.


